



LoRA Exchange (LoRAX): 以 1/100的成本提供精细调校LLM服务

Predibase是一家总部位于美国加利福尼亚州旧金山的公司,是首个面向开发者的商用低代码声明式ML平台。最近,Predibase宣布其平台已全面上市,并为大型语言模型增加了新功能。该公司在3轮融资中总共筹集了2850万美元。最近一次融资是在2023年5月31日进行的A轮融资,由Felicis领投,募集资金达到了1220万美元。
// 关于Predibase公司 //
ChatGPT掀起的人工智能的第N次浪潮渐渐进入浮尘落地后的实战期。现在国内基本上区分出三大集团:
一、 直接与OpenAI竞争的通用大语言模型,比如百川
二、投资硬件提供算力资源的云厂商。通用云厂商如阿里。专注高性能计算(HPC)的比如最近在北交所IPO的并行科技,其董事长陈健相信“大模型对算力的需求极大,动辄十几亿,光电费就要几百万,企业采用租用算力是风险最小、资金利用最优的方式” (并行科技陈健:超算架构大模型算力,买不如租!)
NineData便是第三类。作为多云多源的云原生智能数据管理平台,NineData使用大模型来做自然语言数据库查询,异构数据库迁移的表结构改写,SQL语法优化建议等。在数据库领域的专门训练弥补了通用的大模型的不足。通过LoRA模型来训练基础模型,构建的问题包含一个具体的问题和多个表结构,并校验产生的SQL语句,通过万级别的样本问题集和匹配的查询SQL进行针对性训练,提高了多表Join相关问题的查询效果。同时,有针对性的解决基础模型训练过程中的问题,比如灾难性遗忘的问题(即对于基础模型原来能回答好的问题出现了退化)。应用数据库专业技术增加了通用训练样本集,扩大语料后基本解决了这个问题,查询准确率也有有明显的提升。
上面提到的三类之外,国际上还有第四类:提供LLM服务的平台类公司群体,即有巨无霸Huggingface(两个月前以45亿美元估值融资2.35亿)和上周同大家介绍的刚刚崭露头角的Lepton AI(阿里前副总裁贾扬清创立),也有今天同大家分享的Predibase。
本篇是翻译Predibase的CTO Travis Addair关于LoRA在通用LLM上的使用介绍,他们与NineData采用相同的技术栈,区别在于Predibase提供通用服务和NineData在数据库专属域提供最终业务服务。
原文链接:https://predibase.com/blog/lora-exchange-lorax-serve-100s-of-fine-tuned-llms-for-the-cost-of-one
希望将生成式人工智能应用到生产中的开发人员很快就发现,当针对特定任务进行微调时,LLaMA-2-7b 等更小更快的专用 LLM 会击败 GPT-4 等更大的通用模型。但是,要将所有这些经过微调的 LLM 投入生产,为您自己的专用 LLM 集合提供服务的成本效益至少要与通过 API 使用一个通用 LLM 的成本效益相当--如果每个经过微调的 LLM 都需要一套自己的专用 GPU 资源,这是不可能的。
在这篇博文中,我们将介绍我们针对在生产中提供微调 LLM 所面临挑战的最先进解决方案,解释 Predibase 的 LoRAX 服务基础架构如何在引擎盖下工作,并向您展示如何立即免费开始在 Predibase 中微调和提供 LLM。
使用 LoRA 精细微校调和服务 LLM
微调深度神经网络的传统方法是更新模型的所有参数,作为训练过程的延续。对于拥有数十亿个参数的大型语言模型来说,这需要大量 GPU 内存(每个可训练参数都相当于微调所需的约 4 倍额外开销)和存储空间(每个模型检查点需要数十 GB)。
为了降低微调对资源的消耗,低秩自适应性(Low Rank Adaptation,LoRA)等参数高效微调技术引入了由少量新参数组成的适配器进行训练,而原始模型参数则保持冻结。尽管只训练了少量参数,LoRA 却实现了与完全微调相当的性能。在提供服务时,原始模型参数和新的适配器参数可作为单一部署一起加载。
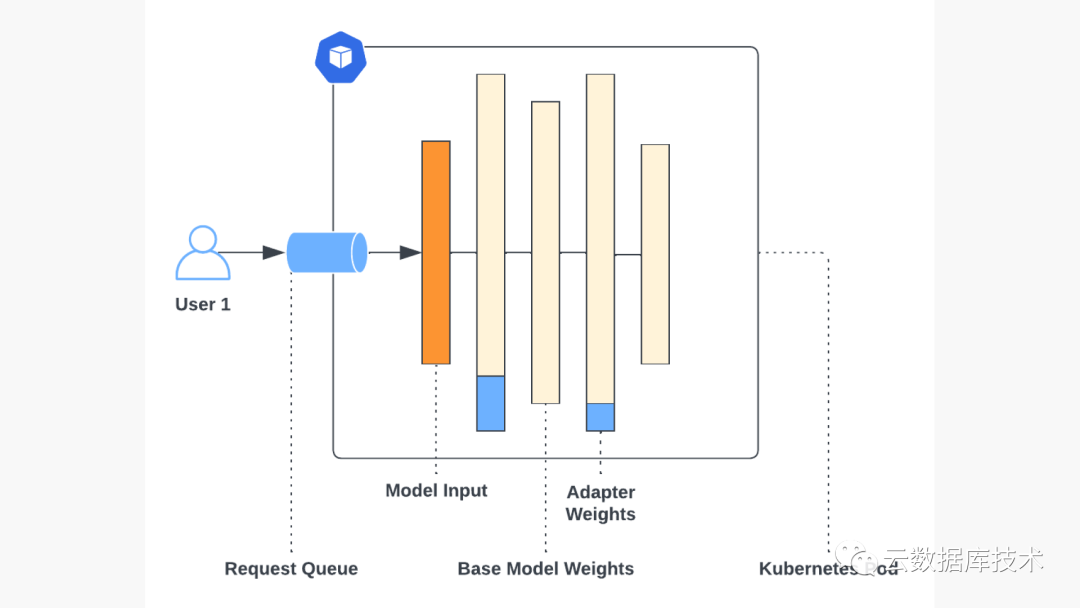
这样做的弊端是,如果使用 LoRA 对多个模型进行微调,则每个模型都需要与原始 LLM 一起部署在一组专用资源上,这样就会很快增加资源。虽然像 ChatGPT 这样的通用 LLM API 提供了非常便宜的每个令牌定价,但为微调的 LLM 提供服务却不是这样,因为微调的 LLM 通常需要建立一个专用部署。在 AWS 中按需定价的 g5.2xlarge 中为自定义 llama-2-7b 模型提供服务,每小时将花费 1.21 美元,或每月 24x7 服务费约 900 美元。假设您有数十到数百个经过微调的 LLM 需要服务,无论您查询 LLM 服务的频率如何,您的云账单很快就会膨胀到每月数万美元。
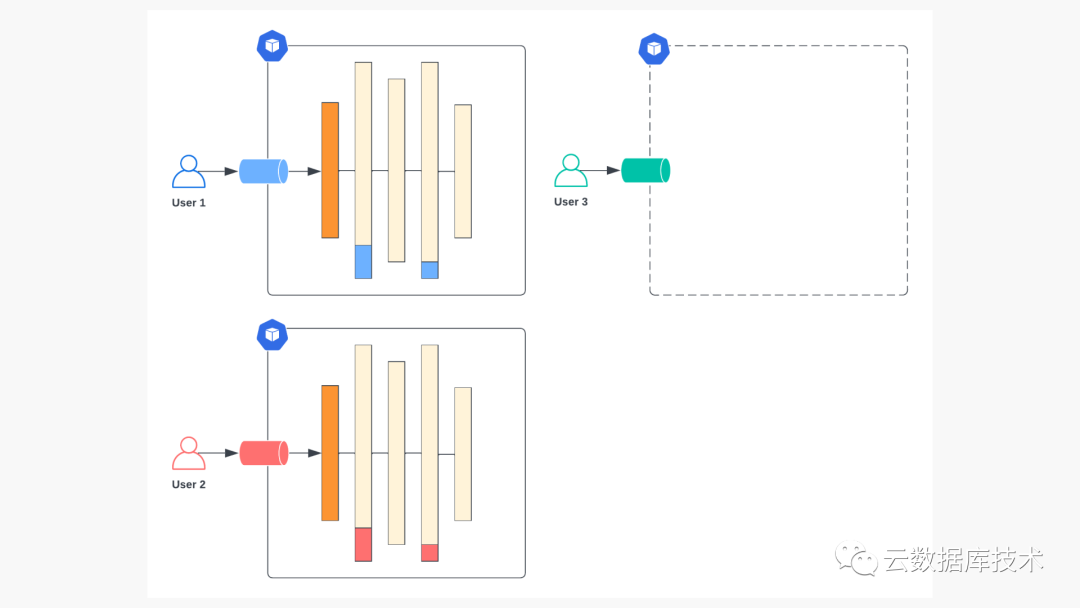
为多个微调模型提供服务的简单方法。用户 3 的模型(绿色)刚刚调配完毕,整个服务堆栈已全面部署。
虽然每个微调模型的专用部署在操作上很容易实现,但却远非最佳。如上图所示,大部分开销来自基本模型参数,而每个部署之间的参数都是相同的。微调模型特有的部署部分--适配器权重--只占总参数的不到 10%,在大多数情况下远远低于 GPU 内存容量。
LoRA Exchange (LoRAX) 简介
1. 动态适配器加载(Dynamic Adapter Loading),允许每组微调的 LoRA 权重在运行时收到请求时及时从存储中加载,而不会阻塞并发请求。
2. 分层权重缓存,支持在请求之间快速交换 LoRA 适配器,并将适配器权重卸载到 CPU 和磁盘,以避免内存不足错误。
▋动态加载适配器
与在初始化过程中预载所有模型权重的传统服务基础架构不同,LoRAX 只在初始化过程中加载预训练的基础 LLM 权重,并在运行时动态加载每套经过微调的 LoRA 适配器。
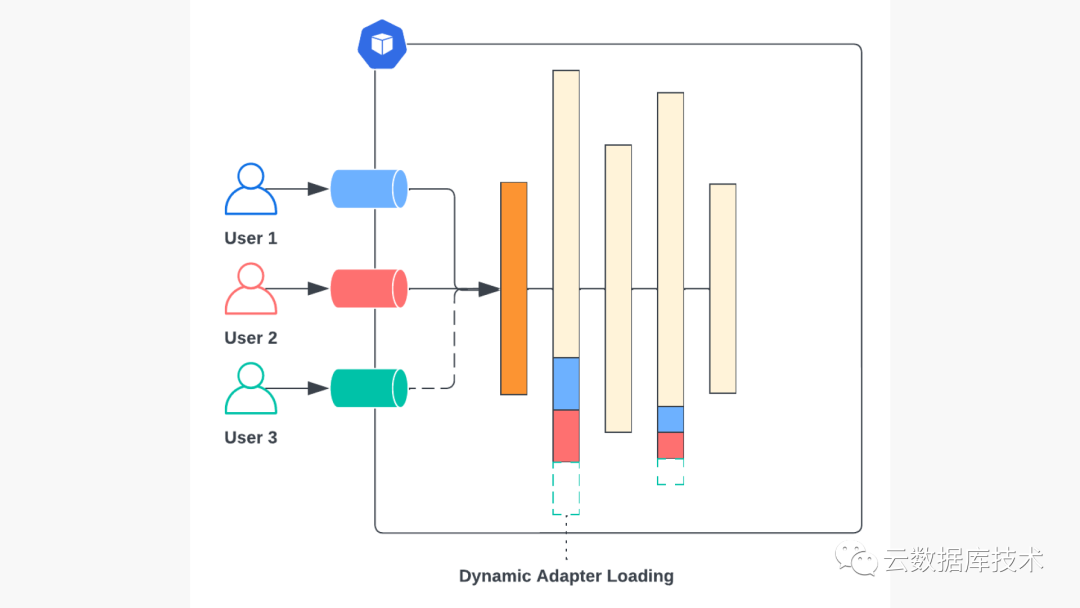
多个并发微调模型请求的动态适配器加载概览。用户 3 的模型(绿色)在后台加载,其他请求照常进行。
为避免阻塞其他用户正在进行的请求,LoRAX 系统会为每个微调适配器维护一个单独的请求队列。当新微调模型的适配器权重被动态加载时,其所有相关请求将在队列中等待,而其他请求则照常进行。在实践中,我们观察到动态加载新适配器的开销约为 200 毫秒,比典型的文本生成响应时间要短得多,因此可以在训练完成后立即开始交互式评估微调模型。随着后续标记的生成和对同一模型请求的提交,这种微小的加载成本会被进一步摊销。
▋分层权重缓存
随着越来越多的微调模型被加载到单个 LLM 部署中,内存开销也随之增加。为避免出现内存不足错误(OOM),LoRAX 系统实施了分层权重缓存策略,将适配器权重从 GPU → CPU → 磁盘卸载,以权衡适配器交换延迟和内存开销。
LoRAX 缓存策略的目标是在 GPU 上保留尽可能多的适配器,同时为处理长序列和大请求批次留出足够空间之间取得平衡。当一个适配器确实需要从 GPU 上剔除时,我们会使用最少最近使用(LRU)策略将其转换到 CPU(主机内存)上。这一策略还延伸到缓存的下层,因此我们会将权重从 CPU 中驱逐出去,并在新的适配器权重加载进来时(如有必要)将其从本地短暂磁盘中删除。在最坏的情况下,权重可以从对象存储中重新加载。
将所有这一切整合在一起,就能在一次部署中容纳多达 100 个模型,除非请求量很大,否则无需扩展到额外的副本。
▋多适配器连续批处理
实现高吞吐量文本生成的最重要技术之一是连续批处理,即在每个标记生成步骤之间,随着新请求的到来和旧请求的完成,多个请求可以动态地批处理在一起。
这给在请求之间交换 LoRA 权重带来了挑战。如果同一时间只能使用一组适配器权重,那么任何针对不同微调模型的请求要么需要等待特定适配器的所有活动请求完成(增加了非活动适配器的延迟),要么每隔几步就在适配器之间交换(抵消了连续批处理的效果,从而增加了吞吐量)。
LoRAX 实现了一种公平的调度策略,既能优化总体吞吐量,又能确保请求的每个不同适配器的有效性:
-
在任何给定时间,一定数量的适配器 N(受 GPU 内存限制)将被标记为 "激活",其权重已加载到 GPU 上,并可在解码过程中使用。 -
激活适配器的请求将从各自的队列中排出,并被连续分批处理。在计算每一层的激活时,一个简单的掩码可确保批次中的每个请求都应用了正确的适配器(见下图)。 -
经过一段可配置的时间后,调度系统将以循环方式移动到下一组适配器。在实际操作中,这意味着在活动适配器组中停留时间最长的适配器将被驱逐,而等待时间最长、请求队列未清空的适配器将成为活动适配器。交换活动适配器前的等待时间可以增加,以优先考虑吞吐量;也可以减少,以优先考虑延迟。
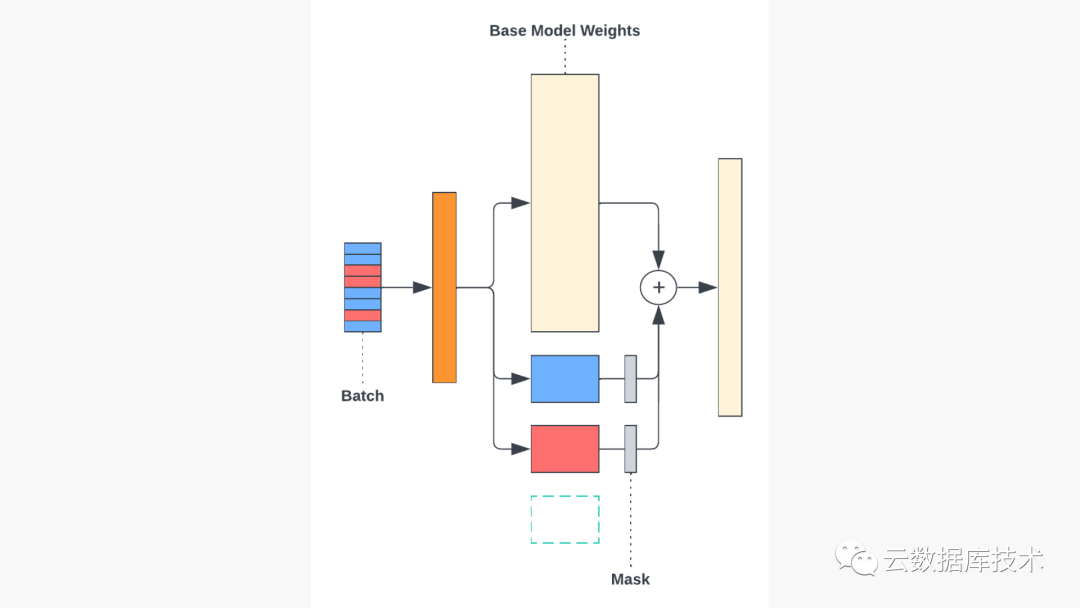
在单个批次中使用多个适配器进行解码。掩码可确保只使用正确的适配器来处理批次中的每个元素。
使用 LoRAX 微调和服务 LLaMA-2-7b
▋Predibase:开源人工智能基础设施
Predibase 平台提供了一个统一的基础设施系统,用于构建和提供专门针对您的任务的微调 LLM。Predibase 建立在 Uber AI 开发的开源 Ludwig 框架之上。Ludwig 的声明式界面是将微调和服务系统结合在一起的粘合剂,让您只需几行代码就能构建自定义 LLM 并开始提示它们,而不会失去低级框架提供的灵活性或控制力。
Predibase 基于 Ludwig 的声明式基础,抽象出了管理生产型 LLM 平台的复杂性。Predibase 可自动确定训练和服务作业所需的计算资源,优化资源利用率以防止 OOM 和其他故障事件,并以开箱即用的可靠性和容错性协调作业的整个生命周期。
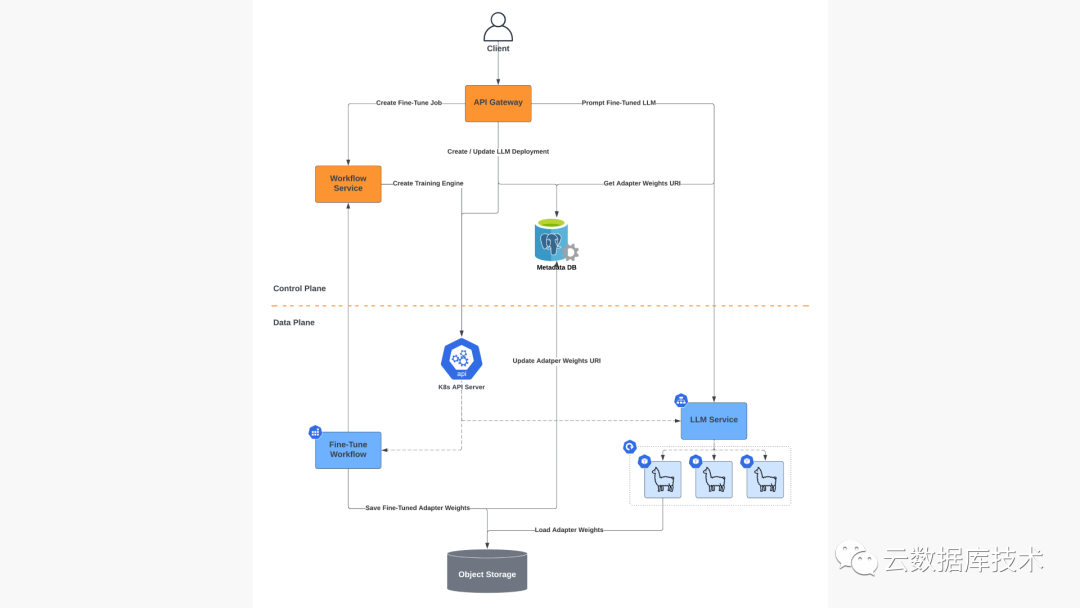
Predibase 采用混合架构,可根据各种因素有效调度作业在不同环境中运行,这些因素包括:
3. GPU可用性:以合理的价格运行在合适的GPU上,包括Predibase自己的专用集群。
▋使用 Predibase Python SDK 的 LoRAX
让我们通过一个示例来了解,如何通过 Predibase Python SDK 使用 LoRAX 对 LLaMA-2-7b 进行微调和查询。如果您想跟进每个步骤,请点击此处查看随附的 Colab 笔记本。
首先,点击这里免费使用 Predibase 14 天。在本教程中,我们假设你正在 Predibase 的托管云中运行。登录后,导航到 "设置 "页面获取 API 令牌,这样就可以通过 Python SDK 开始运行作业了。
运行 pip install -U predibase 安装 Python SDK 后,只需登录即可开始微调 LLM:
# First-time setup to provide your API token$ pbase loginAPI Token: ...🚀 Welcome to Predibase, 'username'!
from predibase import PredibaseClientpc = PredibaseClient()
让我们从提示共享的 Llama-2-7b 聊天模型开始,看看它能否为我们生成一些 Java 代码:
llama2_7b = pc.LLM("pb://deployments/llama-2-7b-chat")result = llama2_7b.prompt("Write an algorithm in Java to reverse the words in a string.")print(result.response)
你可能会得到这样的回复:
Of course! Here is an algorithm in Java to reverse the words in a string:public static void reverseWords(String str {// Split the input string into an array of wordsString[] words = str.split(" ");// Reverse the array of wordsfor (int i = words.length - 1; i >= 0; i--) {System.out.print(words[i] + " ");}}Please provide the input string for which you would like me to reverse the words.
不错,但有点冗长。如果我们尝试对基础 llama-2-7b 模型进行微调,使其准确生成我们正在寻找的代码呢?
下载 CodeAlpaca 数据集,在微调过程中,我们将使用该数据集为模型提供预期输入和输出的示例:
!wget https://predibase-public-us-west-2.s3.us-west-2.amazonaws.com/datasets/code_alpaca_800.csv
现在让我们进行微调:
prompt_template = """Below is an instruction that describes a task, paired with an inputthat may provide further context. Write a response that appropriatelycompletes the request.### Instruction: {instruction}### Input: {input}### Response:"""llm = pc.LLM("hf://meta-llama/Llama-2-7b-hf")dataset = pc.upload_dataset("code_alpaca_800.csv")model_ft = llm.finetune(prompt_template=prompt_template,target="output",dataset=dataset,).get()
我们现在有了一个为代码生成而微调的 Llama-2-7b 模型,但它的实际性能如何呢?让我们使用 LoRAX 来测试我们的模型,将经过微调的适配器权重动态加载到现有的 Llama-2-7b 基本模型部署中。在 Predibase 中,这只需几行代码即可实现:
llama2_7b = pc.LLM("pb://deployments/llama-2-7b")llama2_7b_ft = llama2_7b.with_adapter(model_ft)result = llama2_7b_ft.prompt(data=dict(instruction="Write an algorithm in Java to reverse the words in a string."input="The quick brown fox"))print(result.response)
快速浏览一下回复,我们就会发现微调模型比聊天模型更精确、更切题,同时还能提供正确的代码:
public static String reverseWords(String str) {String[] words = str.split(" ");StringBuilder sb = new StringBuilder();for (int i = words.length - 1; i >= 0; i--) {sb.append(words[i]).append(" ");}return sb.toString();}public static void main(String[] args) {String str = "the quick brown fox";System.out.println(reverseWords(str));}}
结束语
在 Predibase,我们相信未来将是针对您的任务进行微调的专业化 LLM。即使您只需要一个销售点聊天机器人,也可以让 LLM 执行生成法文诗歌等通用任务,而不是用数千亿个参数来煮沸海洋,更小更专业的 LLM 才是将生成式人工智能投入生产的最具成本效益和性能的方式。但今天的 LLM 服务基础设施并不是为服务各种专业模型而构建的。要实现更加精细化的未来愿景,就必须重新考虑服务堆栈,将精细化放在首位。
LoRAX 是构建专用 LLM 的真正微调优先平台的第一步。在未来几周和几个月内,我们将分享更多关于如何在此基础上扩展微调功能的信息,例如
-
通过更智能的特定任务解码加快推理速度。 -
扩展模型的上下文长度,以处理超长的输入序列。 -
使用少至 10 到 100 个示例进行微调。
▋致谢
感谢 Magdy Saleh、Jeffrey Tang、Wael Abid、Arnav Garg、Noah Yoshida、Julian Bright 和 Piero Molino 对本研究的贡献。
-
beat bigger general-purpose models:http://opensamizdat.com/posts/chatgpt_survey/
-
performances comparable to full fine-tuning:https://arxiv.org/abs/2106.09685
-
continuous batching:https://www.usenix.org/conference/osdi22/presentation/yu
-
Ludwig:https://ludwig.ai/
-
predibase:https://predibase.com/
-
2-week free trial:https://predibase.com/free-trial
-
join the community:https://join.slack.com/t/ludwig-ai/shared_invite/zt-mrxo87w6-DlX5~73T2B4v_g6jj0pJcQ -
NineData:https://www.ninedata.cloud/





