



数据火器库 - 八卦系列之罗马方阵:PostgreSQL 模块化设计

1. 历史
PG的牛X,它作者的牛X,网上无数硬核也有无数的软文,大家自己找。
笔者面对客户分析那种数据库比较适合业务的时候,为了东家的业务(和自己的炫技),常常会谈到PostgreSQL是学院派 ,MySQL是野路子。演绎为,MySQL是一帮高手(hacker) 在走江湖的时候,需要解决现实问题,于是写了MySQL来做数据管理;PostgreSQL是某PhD青年讲师,为了展示数据库RDBMS的博大精深,并且为了可以给学生讲解数据库系统的各个部件,开发了一个课件。虽然是演绎,PG作者能获得图灵奖,侧面也反映该系统的理论价值。
简单的说,两个学生听说了System R论文和项目(搞数据库的同行们装B的必读书目,论文读不懂,至少要八卦一下),说咱们搭个积木练练手,于是写了Ingres。后来觉得不够好,顺手致敬一下"Man Month Mythical 人月神话 - The pilot system and the 2nd system effect"(又是软件工程师装B必读,强力推荐), 重写了一个。名字都不愿意费劲,直接POST(in)GRES了。再后来,又有两个学生需要毕业,顶会刊物论文做KPI,就加了一个语言系统,于是今天的PostgreSQL。
感谢前辈们呀,养活了我们这些靠着大树和平台吃饭的半瓶子醋们。
2、模块架构
公平的说所有的系统产品都是模块化的,即使初期是由某个大牛独立完成(Linux, MySQL), 系统产品必须依赖团队协作,才能真正取得成功,也就是所谓的“正规军”协同作战。因此模块化是必要条件,以支持共同开发,协作调试。严谨的接口interface设计又是关键,保证团队之间的协调的效率。
称为正规军其实是有一定道理的,因为很多现代工业的模式是从军队和战场学来的。华为就自称军事化管理。模块化更可以追溯到罗马方阵时代,两百人队组成一小队,三小队组成一大队,十大队成一军团,于是由60~80人的模块到4~6千人的集团,都有了独立战斗和协调战役的能力。二次大战时的海陆空协同亦是如此。
扯个闲话,这里提到的正规军协同,是当通讯无法用“喊”之后的成建制的系统协同,而不是字面上的。工作中我参加过某战役的KO,问了一个问题,“多少人力可以投入到这个战役?”,发现与会人不少(20+),真正投入的人力不到3个!用战役来形容这种工作,哎,吹牛都这么卷了。一两个人的协同“战役”呀。
八卦总要有个边界,收一下图是网上google来的PostgreSQL的架构图,有兴趣的同学可以参考,写的还是不错的。
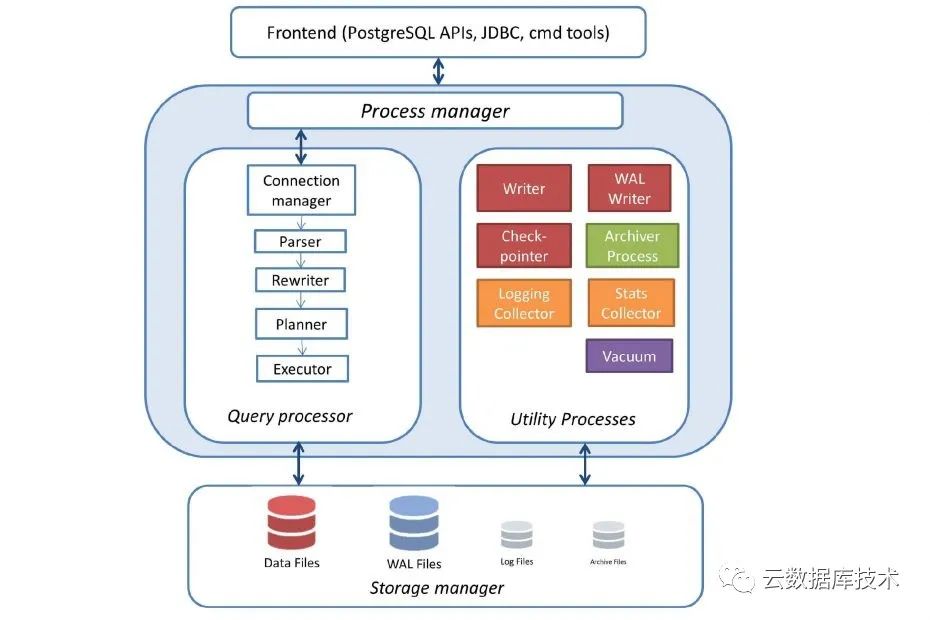
虽然上图画的是PG, 基本上可以覆盖2/3的传统数据库,因为“天下功夫出少林”。大部分经典数据库都是在System R的系统原型上开发的,IBM的DB2自不必说,传说Larry Ellison当年开发Oracle, 不懂得地方就直接电话System R的作者们。
简单举例一个模块吧:(query)rewrite
• 语法兼容:比如DB2中TO_CHAR()和VARCHAR_FORMAT()是语法不同但是语意相同的synonym。这样就可以很容易的增强同其他数据库产品的兼容性。再比如,PG没有SQL Server的datediff,但是可以通过rewrite 用已有的原子op支持. 最近AWS推出的Babelfish便是利用了这个原理。
• 优化选项 :比如WHERE C1 = 1 or C1 = 2 .... or C1=10000可以重写为WHERE C1 IN (1,2,...10000)。于是就可以利用专门为IN提供的优化逻辑,如pre-sort, binary search....
• 类似的还有,transitive closure, query decorelation, etc.
这里重要的不是能够做什么东西,而是这些operation可以在Query Rewrite 模块独立完成,对于流水线pipeline前方的Parser,后方的optimizer,以及执行端的 executor 侵入性极小甚至无感。
模块化的反面典型呢,请移步"MySQL is a pretty poor database, and you should strongly consider using Postgres instead" by Steinar H. Hunderson, 他的批评就是针对的MySQL SQL引擎的模块化设计问题。当然我们是八卦为主,不做MySQL与PG之争,客户随便选。并且在很多情况下,比如简单直接的范互联网TP场景下MySQL很可能是最优解。
3、可扩展性
模块化的另一个好处即是可扩展性。上面我们提到引擎内部模块保证了核心(关系数据库)能力的可迭代,也提供了路径和接口给未来。
3.1 UDF and Stored proc
用户可定义的编程逻辑是SQL语言早期就奠定基石的扩展方式。SQL和关系模型是面向2维表的描述类语言, 它们把行列和表关系阐述到极致,但同时并不擅长其他算法。
早期的数学cos/sin, 统计学avg/sum/stdev是在内部用math library实现的, 对外用built-in function(BIF)呈现。更外延的,就采用用户定义函数(UDF)比如时空计算,ML算法实现等等。UDF和BIF没有本质区别,由于数据库/SQL最早被用在金融(银行账户管理)/制造(波音飞机库存管理)/政府(人口注册)等,所以时间(timestamp/date/year), 简单数学运算(不超过小学四年级水平),字符串查询(人名,地址)和统计学算法等,相对常用且简单,常常内置为BIF;复杂的算法就是UDF了。Stored Proc 一般没有所谓内置的。它的逻辑与通常的应用程序(application)没有本质区别。比如在执行一个信用卡支付操作时,数据库负责记账扣钱支付,常常业务逻辑要求有反盗刷检验(欧美信用卡盗刷的损失一般不会由消费者承担,所以金融机构有很强的利益驱动而实现这个逻辑)。而这个逻辑一般会比较复杂,几个到上百的check point。实现在stored proc里,可以很好的封装,有利于迭代开发。同时stored proc为两个特殊能力提供便利:1)事务原子性 begin ..end ; 2) 与数据库共享内存shared memory space。
题外话:面对任何宣布一键式替代oracle(或者其他商业数据库)的销售,都可以挑战他一下stored proc, pl/sql(O), SQL PL(IBM), PL/pgSQL(PG)
3.2 Foreign Data Wrapper
21世纪早期兴盛联邦数据库(Federated database system) 。其实数据库是个老家伙,几乎今天所有的buzzing word, cutting-edge technology, 都可以追溯的70s和80s。联邦数据库的理论概念至少可以追溯的上世纪80年代。但是其成为开发热点是上世纪末本世纪初,当时的初衷是统一管理多个关系数据库(NoSQL, Bigdata等数据源还未诞生)。联邦数据库并没有发展到爆发程度,老兵换新装,今天大家看到的data lake概念,包括databricks 的lakehouse 架构,都有联邦federation的影子和实质。
PG的FDW是基于SQL standard(2008)的SQL/MED ("Management of External Data") extension。在PG 9中实现的,PG官网上就列述了13大类一两百个。笔者N多年前就是根据Apache HAWQ ,prototype了openGauss的SQL on Hadoop, 现在已经正式商用化为SQL on Anywhere。这是FDW最常用的地方。因为其module模块化能力,每个FDW开发都是独立的,而且比较容易与PG优化器集合,所以从oracle_fdw, hdfs_fdw,到clickhouse_fdw。从小小的fdw的开发平台,可以窥到最新的数据库trend。
另,PG extension常常是FDW必需的组件,但不限于FDW。比如PostGiS就是最常见的extension使用。本篇只是为了举例,就不覆盖了
3.3 复杂数据类型
PostgreSQL除了简单数据库类型(numeric, date/time, string/char),还支持机会所有的复杂类型,包括XML, Array,composite,Geometric和JSON。其中JSON(准确来讲是JSONB, B for binary or better)随着web 和mobile服务的发展,成为最常提及的一种复杂数据格式,也反映在MongoDB的市值250亿美刀上。
4、数据库事务性和Isolation
数据库开发人员面试/晋升答辩必备。除非你是天天围绕事务性的code滚打,被绕进坑里爬不出来的机会非常大。
笔者参与的数据库的相关面试没有100,也有50了。自己记性很差,背不过RU, RC, CS RR, SI,Serializable 之间对应的anomalies。让我慢慢根据逻辑推导出来,一般八九不离十。但是面试答辩中的快问快答,就容易晕菜。每次面试之前都要准备一次。这方面的网上技术文章很多,除了少数有新意的,基本上都是读书笔记水平,个别的把别人的英文blog翻译成中文,直接属上自己的名字,就有点过了。
我一般为了防止老年痴呆,偶然看如下三个材料。最常用的是第二个,面试之前临时抱佛脚的:
• A Critique of ANSI SQL Isolation Levels。1995年微软研究院出品。直接挑战SQL-92中从表现形式“Dirty Reads, Non-Repeatable Reads, and Phantoms”定义的隔离级别,并且提出Snapshot Isolation概念
• A Critique of ANSI SQL Isolation Levels - the morning paper。上面经典paper的读书笔记,尤其是它的第一张图把8个异常现象和6个隔离级别画的很清楚
• CMU Advance Database 课件 by Prof. Andy Pavlo.
对于实现方式,一般是用lock-based锁或者MVCC。不同是实现方式,也就引起上面的隔离级别的分支。分布式集群中的事物的复杂度就指数型上升了。在面试的时候,如果你很牛,可以提出HLC和truetime来炫技,如果一般的话,建议不要给自己挖坑。这个题目是“茴”字四种写法在数据库中的典型反例。
上面写的东西就是凑字数,大家千万不要太认真。主要是为了引出下面的八卦。
4.1 八卦一定要认真
回想起2021年7月东京奥运会上,那个洛桑理工的数学女博士后公路自行车比赛超越职业战队,获得金牌的传奇。真说不清什么是专业什么是爱好。
PostgreSQL社区也有这么一位,请看2012 VLDB作品:Serializable Snapshot Isolation in PostgreSQL。两个作者其中一个作者Kevin的email是从wicouts.gov来的,对,就是威斯康星州法院。
文章中的应用场景是威斯康星州法院的例子
However, snapshot isolation does not guarantee serializable behavior; it allows certain anomalies [2,5]. This unexpected transaction behavior can pose a problem for users that demand data integrity, such as the Wisconsin Court System, one of the motivating cases for this work.
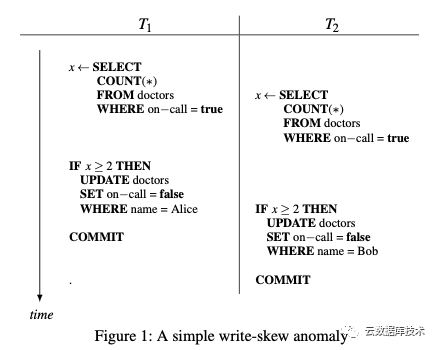
例子中的业务场景是法院的值班医生。限制条件是必须有至少一个医生值班。两位医生Alice and Bob在下班前,先看看值班医生数是否>=2, 如果"yes",他/她就下班了。如果上图的两个事务(transaction)顺序执行的话,是不会有问题的。但在并发concurrency时,用SI(Snapshot Isolation)的方式,两个T读同一个Snapshot, 返回值是2。结果就是Alice and Bob双双下班回家去,不管病人死与活。
江湖传言说这个Kevin其实是法院下属的监狱系统的,实际场景不是医生,而是狱警。八卦的真谛是坚决不证伪,所以我同客户分享SSI的时候,直接上《Prison Break越狱》,大家可以移步豆瓣了。

在当时的PostgreSQL实现了SI, 但是无法解决上面的问题。看起来有像一个比较实际的问题,总不能让病人(犯人)病死(越狱)吧,于是一个开源社区产品经理们合计了一下(我编的,社区多采用你牛你上的原则), 2011.9.11 GA PostgreSQL 9.1 release note。
后来同样在PG生态上的分布式TP数据库cockroachDB,也支持同样的Serializable。
上面提到isolation level有6个隔离级别(茴字才四种写法,鲁迅说过)。事实上,RDBMS常常只用2~3个,PostgreSQL的default是RC,MySQL的default是RR。虽然大部分成熟的关系数据库都有能力提供更高级别的能力,实际业务中常常不需要,或者说买不起,every feature coming with a cost。
虽然我知道保时捷跑车很好,我偏偏喜欢自己的12年新25万公里的本田奇域(穷是俺的生命的原动力)。同客户交流也一样,可以讲牛X的东西,选型是要按合适的来。这篇扯文的初稿骨架就是在近八年新的Early 2014 MacBook Air 上完成的。
最后,资料来源
System R:https://www.researchgate.net/publication/220421331_A_History_and_Evaluation_of_System_R
华为军事化管理:https://www.sohu.com/a/241479284_100085094
罗马方阵:https://baike.baidu.com/item/%E7%BD%97%E9%A9%AC%E6%96%B9%E9%98%B5/10008743
PostgreSQL的架构图,从此盗图:https://distributedsystemsauthority.com/postgresql-high-performance-guide-architecture/
PG 兼容datediff:https://www.sqlines.com/postgresql/how-to/datediff
PG FDW 13大类一两百个:https://wiki.postgresql.org/wiki/Foreign_data_wrappers
openGauss的SQL on Hadoop:https://support.huaweicloud.com/twp-dws/dws_11_0026.html
Gauss SQL on Anywhere]:https://www.bookstack.cn/read/openGauss-2.1-zh/Developerguide-SQL-on-Anywhere.md
A Critique of ANSI SQL Isolation Levels:https://arxiv.org/pdf/cs/0701157.pdf
A Critique of ANSI SQL Isolation Levels - the morning paper:https://blog.acolyer.org/2016/02/24/a-critique-of-ansi-sql-isolation-levels/
CMU Advance Database 课件:https://15721.courses.cs.cmu.edu/spring2020/) by Prof. Andy Pavlo.
Serializable Snapshot Isolation in PostgreSQL:https://arxiv.org/pdf/1208.4179.pdf
注:原稿成于2022初,部分数据已经变化,如MongoDB市值。
THE END






